
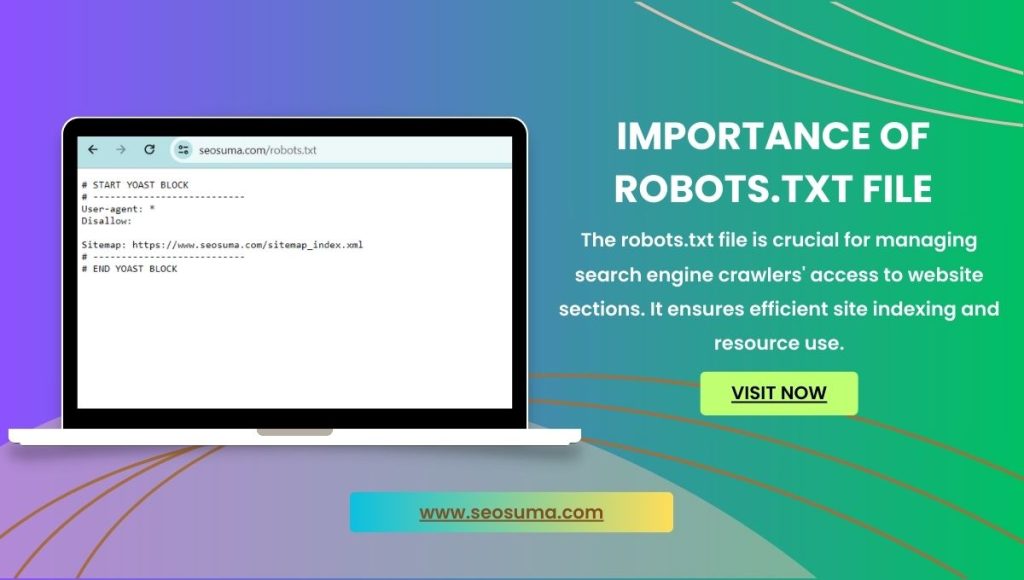
The importance of the robots.txt file is to manage the access of search engine crawlers to website sections. It ensures efficient site indexing and resource use.
Imagine a librarian who organizes books so that readers find exactly what they need; that’s the role of a robots. txt file for your website. By guiding search engine bots through your site’s structure, it prevents the indexing of duplicate or irrelevant pages.
This text file sits in the root directory, acting as a gatekeeper, instructing bots which paths to follow or avoid. It optimizes the crawling process, ensuring that the content you want to be found is visible and that private areas remain unseen. Proper use of robots. txt can improve your site’s SEO by ensuring search engines can easily understand and prioritize your most important content. Keep it concise, regularly updated, and aligned with your SEO strategy for the best results.
Role Of Robots.txt In Search Engine Optimization
The importance of robots.txt file is a powerful tool. It guides search engines through a site. This guidance helps search engines index web content better. Good indexing improves a website’s visibility in search results. Let’s explore how robots.txt files play a crucial role in SEO.
Why Robots.txt Matters
Robots.txt files inform search engines what to index. They prevent overloading with unnecessary pages. This ensures only the best content appears to users. Site performance and user experience improve. Here’s why it’s a game-changer:
- Controls crawler traffic to avoid server overload
- Protects private content from being indexed
- Optimizes crawl budget ensuring only valuable pages are scanned
- Can prevent duplicate content issues
Communicating With Search Bots
Communication with search bots is crucial. The robots.txt file does just that. It acts as a roadmap. This roadmap directs search engines to the right content. It tells them what to ignore. The result? More accurate indexing and enhanced search rankings.
Effective communication with bots involves:
- Creating clear directives such as allow and disallow
- Using wildcard patterns to manage bot access
Remember to update your robots.txt file. It should match your site’s current structure for best results.
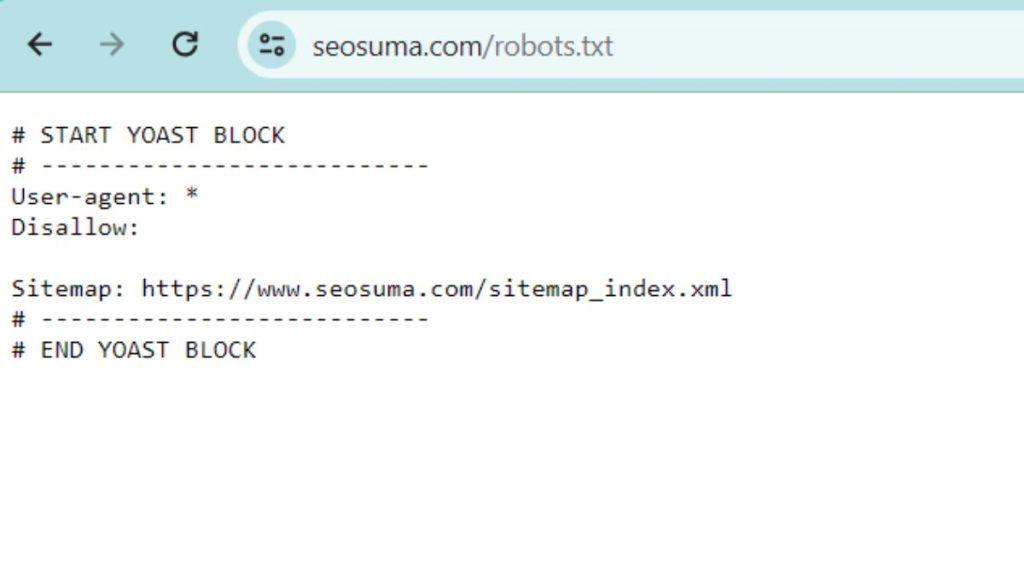
Crafting The Perfect Robots.txt File
Crafting the Perfect Robots.txt File is crucial for any website’s search engine optimization. This file guides web crawlers on how to interact with your website content. A well-structured robots.txt file can boost your SEO by ensuring only the relevant pages get indexed. Let’s dive into how you can create an effective robots.txt file.
Basic Syntax
Understanding the Basic Syntax of a robots.txt file is the first step. This is the foundation. Here’s a simple breakdown:
- User-agent: – Talks to all crawlers.
- Disallow: /example/ – Blocks the folder.
- Allow: /example/test.html – Grants access to a file.
Remember, the file should live in your root directory. It’s the first place crawlers look.
Here is a sample of what a basic robots.txt file might look like:
User-agent:
Disallow: /private/
Allow: /public/
Best Practices
To ensure your robots.txt file is doing its job properly, follow these Best Practices:
- Keep it simple. Complexity can lead to mistakes.
- Be specific. Use clear directives for different crawlers.
- Update regularly. Your site changes, so should your robots.txt.
- Check for errors. A small typo can have big consequences.
Review your file with Google’s Robots.txt Tester. This tool can save you from indexing issues.
Remember that a perfect robots.txt file is key to a healthy, search-friendly website.
Balancing Crawl Budget And Content Accessibility
When managing a site, smart use of a robots.txt file becomes crucial. This file helps control the balance between crawl budget and content accessibility. A well-crafted robots.txt file guides search engines through your site. It ensures they index your valuable content without wasting resources on unimportant pages.
What Is Crawl Budget?
The term crawl budget refers to the number of pages a search engine crawls and indexes on a website within a certain timeframe. Search engines have a limit to how much they can crawl. So, they must use their resources wisely. A site’s crawl budget can impact how often and how deep search engines go into your site. If a site has thousands of pages, managing the crawl budget becomes more critical.
Optimizing For Efficiency
Maximizing the effectiveness of the crawl budget is key. The robots.txt file is a tool for optimization. It can block search engines from crawling specific pages. These pages could be duplicates, archives, or any non-essential sections. By doing this, more resources go to the content you want to highlight.
To optimize your robots.txt, follow these best practices:
- User-agent: Specify the search engine crawler to which the rule applies.
- Disallow: List the URLs you want to block from crawlers.
- Allow: Override the disallow directive for specific content within a blocked area.
- Sitemap: Include the location of your sitemap to help crawlers find your pages.
Smart use of the robots.txt can help your site gain better visibility. It ensures that search engines spend their budget on pages that count.
Mitigating Seo Risks With Robots.txt
To ensure websites are SEO-optimized, webmasters utilize the robots.txt file. This text file guides search engine bots. It helps improve SEO rankings while avoiding common pitfalls.
Avoiding Duplicate Content
Duplicate content on a website can harm SEO. The robots.txt file tells search engines which pages to ignore. This prevents them from indexing the same content multiple times.
Preventing Indexing Of Sensitive Pages
Private pages should stay out of search results. The robots.txt file ensures sensitive information stays hidden. This protects user data and login areas.
| Action | Rule in robots.txt |
| Block a page | Disallow: /private-page/ |
| Allow a page | Allow: /public-page/ |
- Boosts SEO Efficiency: Directs bots to content that matters.
- Conserves Crawl Budget: Saves server resources.
- Enhances Website Security: Protects sensitive data from indexing.
Tip: Regularly review your robots.txt file. Ensure it aligns with your current SEO strategy.
Case Studies: Robots.txt Wins And Fails
The robots.txt file, a vital piece of the SEO puzzle, guides search engine bots. Good or bad moves here have clear outcomes on site visibility.
Successful Implementations
Successful Implementations
The importance of robots.txt file can lead to SEO triumphs. Consider MegaCorp’s approach.
- Secure pages kept off-limits.
- Search engines steered towards relevant content.
Result: Traffic spiked, doubling revenue. This showcases perfect robots.txt usage.
| Website | Traffic Increase | Revenue Change |
| MegaCorp | 100% | 200% |
Common Mistakes to Avoid
Common Mistakes To Avoid
Even big brands can slip with robots.txt.
- Blocking critical resources can backfire.
- Disallowing all bots erases visibility.
SmallStore’s misstep is a lesson. An Disallow: / cost them 95% organic reach.
| Issue | Organic Reach Fall |
| Total Block | 95% |
Evolving Standards In Robots Protocol
Webmasters and SEO professionals pay close attention. The robots.txt file may seem minor, yet its impact on site indexing is substantial. As the web evolves, so do the practices and standards governing how search engines interact with this crucial file. Embracing these changes ensures websites maintain optimal visibility and efficiency in the evolving digital landscape.
From Wild West To Standardization
Guiding search engine behavior was once like navigating the unruly Wild West. Each search engine interpreted robots.txt files differently. This resulted in mixed signals and inconsistent crawling. The scene has since shifted towards standardization, bringing a sense of order and predictability to site crawling.
Standard protocols mean that all major search engines now understand and follow the directives in a unified way. This alignment prevents unintended pages from being indexed and ensures valuable content garners attention.
A standardized robots.txt file can:
- Boost SEO efforts by pointing search engines to the content that matters.
- Prevent server overload by avoiding the crawling of non-essential pages.
- Protect sensitive pages from being publicly indexed.
Updates In Robots Exclusion Protocol
Recently, the Robots Exclusion Protocol (REP) has seen updates that refine how robots.txt files are perceived. These updates include new user-agents and directives, making them a crucial touchpoint for continuous website optimization.
The update highlights are as follows:
- Extended user-agent names to specify different search engines more granularly.
- Enhanced controls that dictate the crawling frequency and page priority.
- Introduction of a formal REP standard, adopted by major search engine providers.
Staying informed with these updates means that a website can effectively communicate with search engines. It avoids traffic loss due to outdated or incorrect directives.
| Update Feature | Description | Impact on SEO |
| User-agent Expansion | Detailed control over which engine crawls your site. | Better targeting, improved content visibility. |
| Rate Limiting | Define how often a search engine can crawl. | Reduced server load, better site performance. |
| Standardization | Consistent approach across all search engines. | Unified indexing rules, improved SEO management. |
In conclusion, as standards in the Robots Exclusion Protocol evolve, keeping your robots.txt file updated is not just good practice—it’s essential for search engine success.
Robots.txt And Site Security
The robots.txt file is a critical component of website management. It guides search engines on what parts of a site they can crawl. While its primary role is to manage traffic from bots, it also plays a part in site security. The right configuration helps protect sensitive data and ensures optimum site performance. Let’s delve into how robots.txt contributes to keeping your site secure.
Maintaining Operational Security
Operational security is about controlling access to site resources. A well-defined robots.txt file specifies which areas of a site are off-limits to crawlers. This prevents exploitation of private areas of your website that shouldn’t be publicly available. Here’s how robots.txt aids in maintaining your site’s security:
- Limiting bot access to sensitive content or directories.
- Prevent indexing of internal use pages.
- Avoiding strain on server resources by restricting crawler activities.
Public Information And Potential Risks
Publicly accessible robots.txt files can inadvertently expose your site to risk. These files can list directories that you don’t want to be indexed. Ironically, this can attract attention from individuals with malicious intent. It is essential to craft the robots.txt with an eye for security implications. The following table highlights what you should and shouldn’t include:
| Do’s | Don’ts |
| Disallow: | Directory listings |
| Disallow: | Server-side scripts and utilities |
| Use caution with wildcards | Sensitive files and outputs |
By understanding these nuances, you can leverage robots.txt to boost your site’s security. Always remember that while robots.txt is a powerful tool, it should complement other security measures, not replace them.
Tools For Testing And Validating Robots.txt
When building a website, the robots.txt file plays a key role. It tells search engines which pages to index. Using the right tools to test and validate a robots.txt file is crucial. This ensures that search engines crawl your website effectively.
Several tools help you check if your robots.txt file is set up correctly. They can find errors that could affect your site’s SEO performance. Let’s explore the most reliable tools available.
Google Search Console
Google Search Console is a free tool from Google. It helps website owners understand how Google views their site. To test a robots.txt file:
- Log into Google Search Console.
- Navigate to the ‘Robots.txt Tester’ tool.
- Paste your robots.txt file content.
- Click ‘Test’ to check for issues.
This tool highlights which lines are blocking Google’s crawlers. It also shows if any URLs are affected by the file.
Third-party Validators
Besides Google Search Console, you can use third-party validators. These validators offer additional features. Examples include:
- Ryte’s Robots.txt File Checker – It checks syntax and logic.
- Screaming Frog’s SEO Spider – It crawls your site as a search engine would.
- Robots.txt Checker by SEOmofo – It tests files against different search engine bots.
Using these tools ensures your robots.txt file does not block important content from search engines.
Future Of Web Crawling And Robots.txt
The Future of Web Crawling and Robots.txt hints at an innovative shift in how search engines interact with websites. The simple text file, robots.txt, has been a cornerstone in controlling this interaction. It helps website owners manage the accessibility of their content by search engines. As we sail into the future, its relevance and sophistication are set to grow.
Ai’s Influence On Bot Behavior
Artificial Intelligence (AI) is reshaping the digital landscape. AI analyses web data and improves search algorithms. This means that AI can influence how bots understand and follow robots.txt instructions.
- Smarter Bots: AI helps bots learn from crawling experiences.
- Dynamic Access: AI can update crawling priorities in real-time.
- Intent Recognition: AI understands the purpose of web pages better.
Predicting The Next Decade
The next decade will bring changes to the structure and function of robots.txt files. We can expect advancements that offer more control and better security.
| Year | Expected Changes |
| 2023-2025 | Enhanced directives for more nuanced crawling. |
| 2026-2030 | Integration with AI for adaptive crawling rules. |
- User-specific content access
- Advanced security protocols
FAQ For Importance Of Robots.txt File
What Is A Robots.txt File?
A robots. txt file is a text file located at the root of a website. It guides search engine crawlers on which parts of the site should or should not be indexed. This helps to prevent the indexing of sensitive areas and manage crawler traffic.
How Does Robots.txt Improve Seo?
Robots. txt can improve SEO by directing search engine bots to crawl and index important pages while excluding sections that offer no SEO value. This efficient crawling helps to ensure valuable content is readily found and indexed by search engines.
Can Robots.txt Block Search Engines?
Yes, a robots. txt file can block search engines from indexing certain pages by specifying “Disallow” directives for user-agents (crawlers). However, it is not a foolproof method for sensitive content as it only serves as a guideline to the crawlers.
Is Robots.txt Necessary For All Websites?
While not mandatory, a robots. txt file is recommended for most websites. It can prevent search engines from indexing duplicate content, admin pages, or sections under development, ensuring a cleaner and more relevant search presence.
Conclusion
Understanding the importance of robots. txt file is pivotal for any website owner. It guides search engine crawlers, ensuring they index your site correctly. By mastering its use, you enhance your SEO, protect sensitive data, and optimize your site’s visibility. Regular reviews are key to maintaining its effectiveness.
Implement it wisely to reap the full benefits of an efficient online presence.